leetcode 765 - Couples Holding Hands
leetcode 765 - Couples Holding Hands
We first assign groups to elements in the array.
For example, given array [2, 1, 5, 0, 3, 4], we assign groups as the following:
[0, 1]: group0[2, 3]: group2[4, 5]: group4
To get the group number for a given array element, we can use arr[i] & (~0x1).
As a result, if we represent [2, 1, 5, 0, 3, 4] in group labels, we get [2, 0, 4, 0, 2, 4].
We visualize each group as a vertax of a undirected graph.
The initial connection of these vertaxes are determined by the pairs in the given array.
For example, if the array is [0, 0, 2, 2, 4, 4], we get the following graph:

If the array is [2, 0, 4, 0, 2, 4], we get:
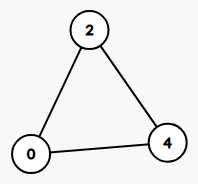
Assume the size of the input array is N, If all the couples are seat next to each other, we want the graph to have exactly N / 2 connected components as shown in the [0, 0, 2, 2, 4, 4] graph.
After we convert the input array into an undirected graph, we convert the problem to:
Given this undirected graph with (N / 2) vertices, and at most two edges for a vertex, what is the minimum swaps needed to convert this graph to a graph that has exactly (N / 2) connected components?
We can observe that, for the given kind of graph, every swap is guaranteed to break one vertex free if it is in a connected component, and thus, increase the total number of connected component by 1.
For example, for the array [2, 0, 4, 0, 2, 4], after we swap idx 0 with idx 3, we get [0, 0, 4, 2, 2, 4]. By doing this, we break vertex 0 free, and increase the connected component count from 1 to 2.
As a result, we can conclude that (the # of components we increased) == (the # of swaps we have to do)
Our gaol is to increase the total number of components to N / 2. Thus we have (origional # of components) + (# of components we have to increase) == N / 2.
As a result, we have:(# of swaps we have to do) == (# of components we have to increase) == N / 2 - (origional # of components)
So, the problem now is converted to find (origional # of connected components) in this undirected graph.
In order to find the origional number of connected components, we can do the following:
If we start with N / 2 connected components, each time we find a new edge between two components, we have to reduce the number of our connected components by 1.
For example, for array [0, 2, 2, 0, 4, 4], we should have 2 connected components: 0 - 2 and 4. If we start our component count at 3, when we see the first pair [0, 2], we know that component 0 and 2 are connected, so we reduce our component count to 2. Then, we see pair [2, 0], but since we already handled [0, 2], we don’t have to handle [2, 0] again since the graph is undirected. So, in the end, we find out that we have 2 connected components in the graph generated by [0, 2, 2, 0, 4, 4].
To achieve this, we can use Union-Find method.
We inspect one pair every time. If the two elements are not already in one group, we know that a new edge is now being added, which means we have to decrease the count of our connected components by 1. Then, we union these two groups.
The implementation is as following:
1 | int minSwapsCouples(vector<int>& row) { |
Articles to read
Some articles I found interesting and want to read…
Stack-sortable array
This algorithm can be used for leetcode 456.
The problem is Stack-sortable permutation. The problem is to try to sort a array of numbers using only a single stack.
The input array is stack-sortable only if it does not contain 231 pattern.
As a result, we can check if the input sequence contains 231 pattern by checking if it is stack-sortable.
Also, we can check if the input sequence contains 132 pattern by reverse the input sequence first, then, check if it contains 231 pattern by checking if the reversed sequence is stack-sortable.
The algorithm is as following:
1 | vector<int> stackSort(const vector<int>& nums) { |
If the given input has a 231 pattern, say input is 231, before 3 is pushed onto stack, 2 will be popped and added to result, but, 1 is less than 2 so it should be added before 2.
Another way to solve the 132 Pattern problem is as following:
We want to find s1 < s3 < s2. We start from the end of the input, and push the elements we get into a stack.
When the value we encounter is greater than the top of the stack, it means that we have a candidate for s2. This is because there are some values after s2 that is less than s2.
Then, we start popping out the numbers from stack that are less than s2 we found. And, we keep track of the max of the numbers we popped out. This max number is the s3 we want to use for this s2. We want to keep the max because we want to have more possibility for s1.
If the value we encounter is smaller than the s3 we recorded, we can say that we have found a s1. This is because the s3 we recorded must have a s2 corresponding to it (s3 < s2). If we found a s1 such that s1 < s3, we know that we have found the s1 < s3 < s2 sequence.
This solution can be found here-space-and-time-solution-(8-lines)-with-detailed-explanation.).
The implementation is as following:
1 | class Solution { |
Algorithm to find majority element
This algorithm can be used for leetcode 229 and leetcode 169.
The algorithm is called Boyer-Moore majority vote algorithm.
A blog for this algorithm can be found here.
This algorithm can solve the following problem: Given an unordered array of size n of int, find all the elements that appear more than floor(n / k) times, with O(k - 1) space complexity and O(n * (k - 1)) time complexity.
The idea is:
- First, we allocate a vector of
k - 1elements calledvals. This is because we can have at mostk - 1elements that satisfy the condition that it appears more thanfloor(n / k)times. We assign unique numbers tovals. We also allocate vectorcountsof sizek - 1to record the number of times each value appears.countsis initialized to all zero. - Then, for each
numinnums, we check allk - 1values.- If
numis the same as one of theval, we increase itscount. - If
numis not the same as any of theval, but we find avalwithcount == 0, we replace thatvalwithnum, and set itscountback to1. - If
numis not the same as any of theval, and for all thevals, we havecount > 0, we then decreacecountfor all thevals.
- If
- Finally, we go through all the
k - 1values we recorded. For eachval, we find its actual appearance time innums, if this count satisfynew_count > floor(n / k), then,valis a solution. If not, we discard thisval.
The c++ implementation is as following:
1 | vector<int> majorityElements(const vector<int>& nums, int k) { |
Algorithm to shuffle an array
This algorithm can be used for leetcode 519. The algorithm is called Fisher-Yates shuffle.
The question is to output the index of an array in a random order (we don’t care the actual value stored at that position), and minimize the number of rand() called and also optimize for space and time complexity.
e.g.: Given array of size 6, the output may look like the following:1
(0, 3), (0, 1), (0, 2), (0, 4), (0, 0), (0, 5)
To achieve this, we can use the following code:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// Get a random number in range [minVal, maxVal].
int getRand(int minVal, int maxVal) {
return rand() % (maxVal - minVal + 1) + minVal;
}
vector<int> solution(const vector<int>& vec) {
int maxVal = vec.size() - 1;
unordered_map<int, int> hm;
vector<int> rtn;
// We loop vec.size() times to get output all the index.
for(int i = 0; i < vec.size(); i ++) {
// Choose a random index in range [0, maxVal].
int randIdx = getRand(0, maxVal);
int currSelectedIdx;
// If we have not seen randIdx before,
// it means that randIdx is the current selected index, and we can just return it.
if(hm.find(randIdx) == hm.end()) {
currSelectedIdx = randIdx;
} else {
// If we have seen randIdx before, it means that randIdx has been selected before.
// And, we need to select the index in hm[randIdx], which is what randIdx represents now.
currSelectedIdx = hm[randIdx];
}
// After the index for current iteration is determined, we need to swap it with the index represented by current maxVal.
// If maxVal still represents maxVal.
if(hm.find(maxVal) == hm.end()) {
hm[randIdx] = maxVal;
} else {
// IMPORTANT !!!
// If maxVal has been chosen before, and it now represents something else.
hm[randIdx] = hm[maxVal];
}
maxVal --;
rtn.push_back(currSelectedIdx);
}
}
This code can be easily extended to 2-D matrix, as we just have to convert maxVal into rowCnt * colCnt - 1. And randIdx has to be converted to (row, col) by using:1
2int row = randIdx / colCnt;
int col = randIdx % colCnt;
Here’s an example of running the algorithm:
1 | init: |
Hide human-readable information in c++ binary
I was recently working on hiding human readable information from a binary compiled from c++ source code.
Here are some of the steps I took to hide as much human readable information from binary as possible.
Encrypt string literals in source code
Since string literals will be put into .rodata section in binary, it is easy for user to read it simply by using the strings command in linux.
There are some ways mentioned online that use template meta programming to encrypt the string literals at compile time (and decrypt at run time). But, it require c++11 standard to work.
Then, we found this post which does not need c++11 to work.
The basic idea is to surround a macro around the string litrals you want to encrypt as following:1
2
3
4
5// In a header file:
// In the place where you want your string to be encrypted:
printf("A string you want to hide in binary: %s", SEC_STR("some secret..."));
The macro SEC_STR does two things:
It adds a suffix
\0\.after stringA.According to the post, encryption is done by directly replace the string literals in binary to the encrypted version. As a result, it needs a way to make sure that the string it locates in binary is the string that user want’s to encrypt. So, after it finds a string in binary, it checks the suffix to see if it is a target string.
It calls the function
decryptStrbefore return the string.By doing this, the actual string (which is the reutrn value of
decryptStr) is used at run-time.
However, the implementation in the blog have several problems:
The
decryptStrfunction uses a buffer to keep the decrypted string.This is a problem when multiple strings needs to be decrypted before they are used, e.g.:
1
2
3
4
5// In helper.h:
// we would like to hide str1 and str2 in binary.
void some_func_call(const char* str1, const char* str2);
// In helper.cpp:
some_func_call(SEC_STR("hello"), SEC_STR("world"));Before
some_func_callis called at run-time, the"hello"and"world"need to be decrypted first.However, when
"hello"is decrypted, the stringhellois stored in the buffer. Then, when"world"is decrypted, it will overwrite thehelloin the buffer. As a result, in thesome_func_call, we get twoworldinstead ofhello world.This problem will also occure when multi-thread is used.
But, this is relatively easy to fix. All we have to do is to use a global
std::map<const char*, std::string>to store the strings we decrypted.When we search for strings with our suffix in binary, there is a chance that there are some random string also have the same suffix. We could potentially break the binary when we encrypt the string.
If we use this method, the encrypted string must have the same length as the origional string, otherwise, we could also break the binary.
To fix these problems, instead fo modifying the binary, we decided to encrypt all raw strings directly in the source file before compile.
This requires a regular expression to match all string literals in source code. A base one is provided here.
- Need to add the working sample.
There are some benifits of using this solution:
We can encode the string literal into anything we want. We don’t have to make sure that the encrypted string has the same length as the origional string.
We can choose the encryption and decryption algorithm we want.
One problem for this approch is that the string we matched using regex can not handle escape characters correctly. All the escape characters are being interpreted literially when doing string encryption.
For example, \n will be treat as two characters, \ and n when doing encryption, instead of being treated as ASCII character LF (10 in ASCII table).
As a result, when we decrypt the string, we do not get the LF character we want, instead, we get \ and n which is not correct.
To fix this, we have to post-process the string matched by our regex into a vector of characters.
During post-process, we convert all the escape sequences into their corresponding ASCII characters. Then, when decrypt, we will get the correct output.
Another problem is that since we have to write the encrypted characters back into our source files, some of the encrypted characters are not printable nor human readable. So, to write them to the source file, we have to write the hexidecimal representation of the characters.
For example, assume \n is encrypted into character sequence abc. Then, in the source file, \n is then replaced with \x61\x62\x63.
Replace __FILE__, __FUNCTION__ and __PRETTY_FUNCTION__
Since __FILE__, __FUNCTION__ and __PRETTY_FUNCTION__ will be replace by pre-processor to string literals, it will be added to the .rodata section of the binary.
To prevent this, we can write our own script to pre-process the source files to replace all these macros to empty string.
For the __FILE__ macro, we can actually easily replace it with the actual file name string when we do our pre-process. But for __FUNCTION__ and __PRETTY_FUNCTION__, it’s harder for a simple pre-process script to actually figure out what they should be replaced with.
This pre-process should be done before we start extracting and encrypting strings.
Do not use virtual methods for classes that you want to hide name
If a class contains virtual methods, its name will be put into rodata._ZTS<class_name> section in the binary. Because this information is needed for dynamic_cast and exceptions.
If the code base does not use RTTI features, -fno-rtti can be added to the compiler flag to prevent these information from being generated.
Some useful links on rodata._ZTI and rodata._ZTS sections:
- https://shaharmike.com/cpp/vtable-part1/
- ftp://gcc.gnu.org/pub/gcc/summit/2003/Getting%20the%20Best%20from%20G++.pdf
- https://stackoverflow.com/questions/49381011/what-does-ztv-zts-zti-mean-in-the-result-of-gdb-x-nfu-vtable-address
Try to remove -rdynamic flag
If our final target is an executable, we can probably remove the -rdynamic flag.
This will prevent a lot of symbols from being exported.
Try adding -fvisibility=hidden and --exclude-libs,ALL
-fvisibility=hidden makes all symbols hidden by default.
--exclude-libs,ALL excludes symbols in all archive libraries from automatic export.
- https://stackoverflow.com/questions/3570355/c-fvisibility-hidden-fvisibility-inlines-hidden
- https://sourceware.org/binutils/docs/ld/Options.html
Add -DNDEBUG as compiler flag
If -DNDEBUG is added, all the assert s are stripped away from source code.
Use strip command to get rid of unneeded sections in binary
Use strip with -s and --strip-unneeded will strip away a lot of sections not needed by binary.
Also, .note.ABI-tag, .note.gnu.build-id and .comment sections can also be removed.
Misc.
- If there are still visible strings left, use
objdumpandreadelfon the object file that the string might come from, to locate which section does the string come from.
todo algorithms
Some of the new algorithms encountered when doing leetcode.
Bi-directional BFS.
Segment Tree.
Uniqueness of topological sort.